- Published on
DynamoDB Scan Vs Query
- Authors
- Name
- Chloe McAree (McAteer)
- @ChloeMcAteer3



DynamoDB is Amazon’s managed NoSQL database service. This blog will be focusing on data retrieval and how it is critical to think about what your data will look like, to make an informed decision about your database design.
When working with DynamoDB there is really two ways of retrieving information — one being scanning and filtering and the other being querying the database! So what is the difference and what should I use?
Before we get started, something we will be talking about a lot is partition keys, so let’s start with a short definition of what this is:
*Partition Key — Is a primary key that DynamoDB uses to partition the data and determine storage.*
First things first, what is scanning?
Scanning involves reading each and every item in the database. It allows you to add filters if you are looking for something in particular, so that only items matching your requirements are returned. However, every single record still needs to be read, as the filter is only applied after the scan has taken place!
Example:
If we had the following data and say we set the employeeID as the partition key once we set up the database:
const item = {
employeeID: { S: "4beb73f0-2fc0-41b2-a8e9" },
startDate: { S: "2020-05-09T17:53:00+00:00" }
name: { S: "example-name" },
title: { S: "example-title" },
}
We could scan the database using the following as our scan params:
const params = {
TableName: "employees",
ProjectionExpression: "employeeID, name",
FilterExpression: "title = :title",
ExpressionAttributeValues: {
":title"ß: {S: "example-title"}
}
};
The above code snippet would scan each item and would then filter for items that have a title the same as the one specified! The filter expression here could filter for any column/attributes in this database (e.g. employeeID, startDate, name, title).
But what is querying and why is it different?
Querying allows you to retrieve data in a quick and efficient fashion, as it involves accessing the physical locations where the data is stored. However, the main difference here is that you would need to specify an equality condition for the partition key, in order to query!
Example:
If we take the same example again:
item = {
employeeID: { S: "4beb73f0-2fc0-41b2-a8e9" },
startDate: { S: "2020-05-09T17:53:00+00:00" },
name: { S: "example-name" },
title: { S: "example-title" },
}
Since we want to query the table this time, we can make use of employeeID as the partition key and we would be able to write query params like this, where our KeyConditionExpression is looking for a particular ID:
queryParams = {
tableName = "employees",
KeyConditionExpression: "employeeID = :id",
ExpressionAttributeValues: {
":id": "4beb73f0-2fc0-41b2-a8e9",
},
}
With using the partition key the query would be more efficient as it doesn’t need to read each item in the database, because DynamoDB stores and retrieves each item based on this partition key value!
But what if we want to Query for something that is not the partition key?
If I want to query another value that is not the partition key e.g. what if we only have the employees name and want to get all their details by that name?
At the minute with our current set up, we would not be able to write a query for this because as I mentioned before — queries need to use the partition key in the equality condition! However, there is still a way we could query for this without having to do a scan.
Secondary Indexes
Using secondary indexes allows us to create a subset of attributes from a table, with an alternative key to create a different access point for query operations.
You can create multiple secondary indexes on a db, which would give your applications access to a lot more query patterns.
We can create a secondary index on DyanmoDB by specifying the partition key for it and naming the index:
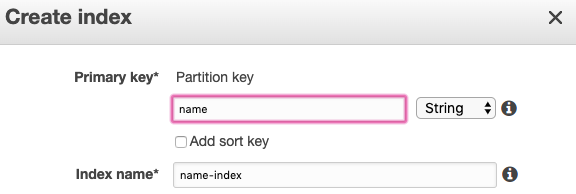
Now with our secondary index set up, we can go ahead and query using it:
queryParams = {
"TableName": "employees",
"IndexName": "name-index",
"ProjectionExpression": "employeeID, startDate, name, title",
"KeyConditionExpression": "name= :name",
"ExpressionAttributeValues": {
":name": {S: "example-name"}
}
};
Notice that we are using the new secondary index within our query. We can now find the employee details by using the employees name!
Setting up secondary indexes do have associated costs, but when working with large amounts of data, it can really increase the performance and efficiency of data retrieval. It can get items based on storage location without having to read every item in the whole database.
To improve efficiency further, you could also look into adding composites keys or indexes which can be made up of a partition key and a sort key.
Scan or Query?
So coming back to our main question, when do we use scan and when does it make sense to use query?
And honestly, it all depends on the size and amount of data you are working with!
If you are working with a small amount of data, you could totally go for scanning and filtering the database and not have to worry about adding all these extra keys. If the data is already small, the scan time won’t take long anyway, so adding in things like secondary keys to partition into even smaller sets, isn’t likely to increase your performance by a significant amount and therefore might not be worth the additional overhead of implementing these.
However, if you are working with large amounts of data, that is likely to keep growing — it is really worth spending time and making sure you choose the right secondary indexes.
When creating a database with indexes, it is really beneficial to spend time considering what queries are you likely to be doing. Understanding what data you will need to retrieve will help you choose your partition keys. Taking the initial time to think this through will make sure your database is set up the right way for you to retrieve data from it in the quickest, most efficient manner! Failure to think about this up front may limit you data access points down the line.